vm.swappiness=0
net.ipv4.tcp_wmem = 4096 16384 16777216
net.ipv6.conf.lo.disable_ipv6 = 1
net.ipv4.tcp_syncookies = 0
net.ipv4.tcp_max_syn_backlog = 8192
net.core.netdev_max_backlog = 16384
net.ipv4.tcp_keepalive_probes = 5
net.ipv4.tcp_keepalive_intvl = 15
net.core.somaxconn = 4096
net.ipv4.tcp_congestion_control = cubic
net.ipv4.tcp_fin_timeout = 15
net.core.rmem_max = 16777216
net.ipv6.conf.all.disable_ipv6 = 1
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv6.conf.default.disable_ipv6 = 1Friday, February 3, 2017
sysctl.conf
Thursday, April 2, 2015
Fix time stamp for chroot sftp user which are showing wrong time stamp
Install/update tzdata
yum update tzdata
copy the time zone file to your chrooted user home directory in etc.
cd /home/chrootuser
mkdir etc
cp /etc/localtime .
cp /usr/share/zoneinfo/America/New_York /home/chrootuser/etc/
Tuesday, December 30, 2014
TC db restore
root@tc:/etc/cron.daily# cat tc-db-restore
#!/bin/bash
mysqldump --opt --skip-lock-tables -utcclient -pxxxx teamcity --extended-insert --routines --add-drop-table | mysql -ubackup -pxxxxx -htcbackup.mydomain.com teamcity
root@tc:/etc/cron.daily# cat tc-backup
curl -v -u user:xxxxxxx --url 'http://tc.mydomain.com/app/rest/server/backup?fileName=TeamCity.zip&addTimestamp=true&includeConfigs=true&includeDatabase=true&includeBuildLogs=true&includePersonalChanges=false' -d tc.mydomain.com
#!/bin/bash
mysqldump --opt --skip-lock-tables -utcclient -pxxxx teamcity --extended-insert --routines --add-drop-table | mysql -ubackup -pxxxxx -htcbackup.mydomain.com teamcity
root@tc:/etc/cron.daily# cat tc-backup
curl -v -u user:xxxxxxx --url 'http://tc.mydomain.com/app/rest/server/backup?fileName=TeamCity.zip&addTimestamp=true&includeConfigs=true&includeDatabase=true&includeBuildLogs=true&includePersonalChanges=false' -d tc.mydomain.com
Sunday, September 14, 2014
Keymap issue with Virt-managr or Virt-viewer
Sometime when you are accessing VM with console you are not able to type the regular character from keybord, ex. if you want press enter from your keyboad but it prints "j" on the screen etc etc.
virsh edit
Change the line below line:
From
To
Then Destroy the VM and start it agian.
virsh destroy
virsh start Monday, July 21, 2014
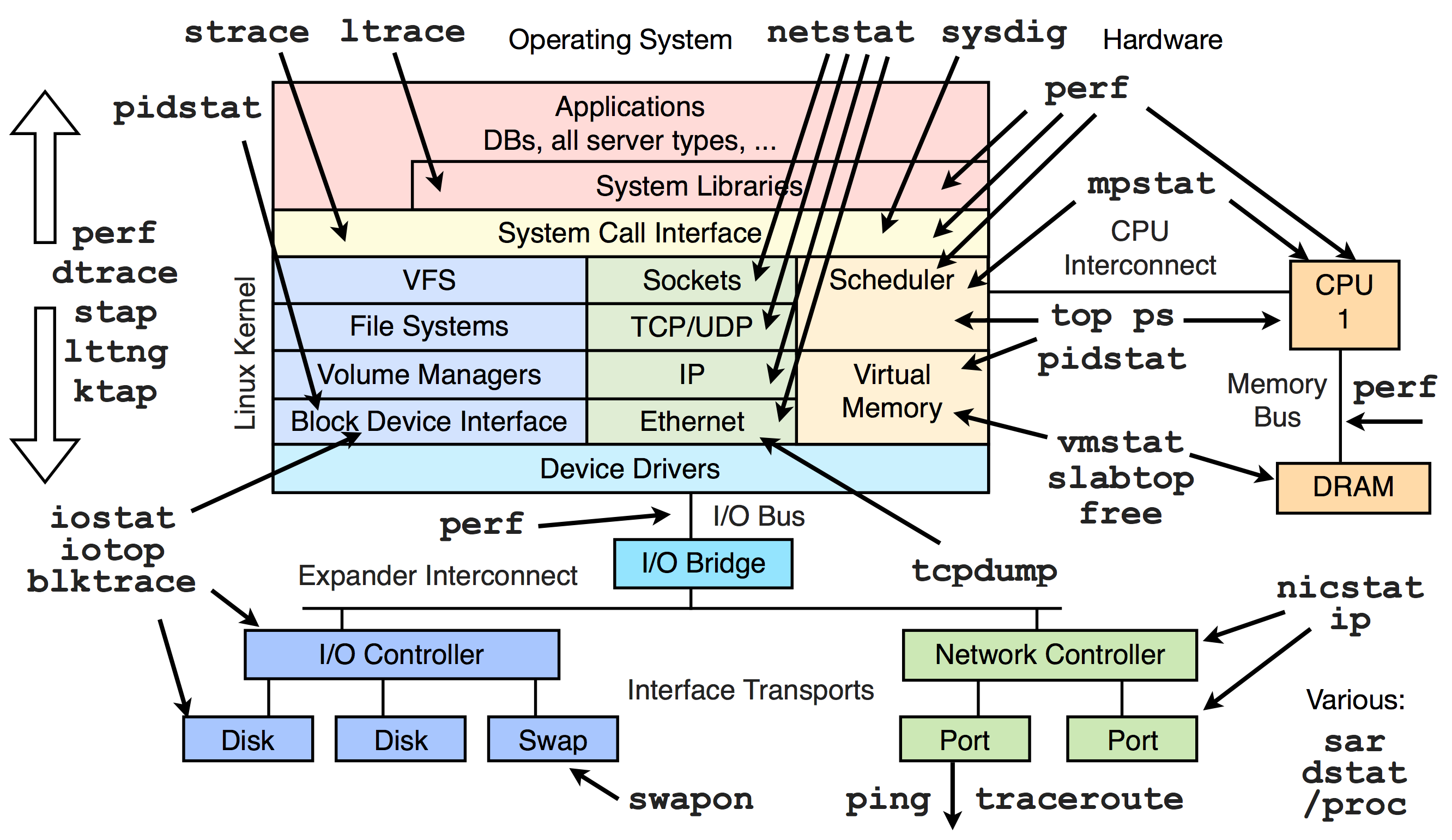
Monday, June 9, 2014
Nginx as CDN
user www-data;
worker_processes 4;
error_log /var/log/nginx/error.log;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
# multi_accept on;
}
http {
server_names_hash_bucket_size 64;
include /etc/nginx/mime.types;
access_log /var/log/nginx/access.log;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
tcp_nodelay on;
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
#### firstApp and secondApp Caching
proxy_cache_path /var/www/cache/firstApp levels=1:2 keys_zone=firstApp_cache:30m max_size=500m inactive=600m;
# secondApp Caching
proxy_cache_path /var/www/cache/secondApp levels=1:2 keys_zone=secondApp_cache:30m max_size=500m inactive=600m;
proxy_temp_path /var/www/cache/tmp;
# secondApp app CDN
server {
listen 5002;
ssl on;
ssl_certificate /etc/nginx/vmh02-cdn01-p91.myDomain.net.crt;
ssl_certificate_key /etc/nginx/vmh02-cdn01-p91.myDomain.net.key;
#listen 443;
server_name vmh02-cdn01-p91.myDomain.net;
location / {
proxy_pass https://AppUrlforSecondApp.mysecondappURL.net/; #// this should point to secondApp server secondApp -
proxy_cache secondApp_cache;
proxy_cache_valid 200 302 60m;
proxy_cache_valid 404 1m;
#root html;
#index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
### app CDN
server {
listen 5008;
ssl on;
ssl_certificate /etc/nginx/vmh02-cdn01-p91.myDomain.net.crt;
ssl_certificate_key /etc/nginx/vmh02-cdn01-p91.myDomain.net.key;
server_name vmh02-cdn01-p91.myDomain.net;
location / {
proxy_pass https://secondAppLInk-stage.AppSitelinkHere.net/; #// this should be the firstApp IP address or LB
proxy_cache firstApp_cache;
proxy_cache_valid 200 302 60m;
proxy_cache_valid 404 1m;
}
}
}Saturday, June 7, 2014
netstat
To display open ports, enter:
netstat --listen
To display open ports and established TCP connections on a Linux host, enter:
netstat -vatn
Run these on the hosts that stop responding.
Additionally, you can use
strace to trace system calls and signals. Specify the "-e trace=network" trace the network-related system calls. As an example, you can run the following command to trace the network signals for the ping -c 3 10.0.0.1command and output to a file called "ping.trace".strace -e trace=network -o ping.trace ping -c 3 10.0.0.1$ nc -z -v mystite.com 80
Connection to mystite.com 80 port [tcp/http] succeeded!
$ curl -I mystite.com
HTTP/1.1 404 Not Found Content-length: 169 Content-Type: text/html Date: Thu, 12 Jun 2014 23:42:23 GMT Server: nginx/1.1.19 Connection: keep-alive
Wednesday, May 14, 2014
One Docker Way
Docker way
Tools Needed:
Packer: Building the images : http://www.packer.io/
Docker: Managing Containder : https://www.docker.io/
Salt: Managing the automated configuration : http://www.saltstack.com/
Packer create identical machine images from a single source configuration. It is easy to maintain.Use packer to build Docker images.
Docker:
- Is like git for filesystems (Docker pull/push/commit)
- Is like Vagrant for LXC containers (docker run / Vagrant up,docker kill / vagrant halt, docker rm/vagrant destroy, Docker file / Vagrantfile)
- It has its own proces space
- It has its own network interface
Containers:
- Containers are isolated, but share OS , bin/libraries
- Containers are process and not VMs, thats why they are so fast
- faster restart
- less overhead
- Copy on write allow to save only deltas
Tuesday, April 8, 2014
Install Teamcity 8.1 on Ubuntu 12.04
Download teamcity
wget -c http://www.jetbrains.com/teamcity/download/
Create dedicated team city user:
adduser --system --shell /bin/bash --gecos 'TeamCity Build Control' --group --disabled-password --home /opt/teamcity teamcity
Install Java
apt-get -y install software-properties-common
apt-add-repository ppa:webupd8team/java
apt-get -y update
echo debconf shared/accepted-oracle-license-v1-1 select true | debconf-set-selections
echo debconf shared/accepted-oracle-license-v1-1 seen true | debconf-set-selections
DEBIAN_FRONTEND=noninteractive apt-get -y install oracle-java7-installer
Install mysql
apt-get install mysql-server
Create database & user
mysql>create user tcclient;
mysql>create database teamcity default charset utf8;
mysql>create user tcclient;
mysql>grant all privileges on teamcity.* to tcclient@localhost identified by 'secure_password';
Download MySQL JDBC driver from oracle site and copy it to /opt/teamcity/data/.BuildServer/lib/jdbc
Create Teamcity server start script in init.d
vim /etc/init.d/teamcity-server
#!/bin/bash
# /etc/init.d/teamcity - startup script for teamcity
export TEAMCITY_DATA_PATH="/opt/teamcity/data/.BuildServer"
case $1 in
start)
start-stop-daemon --start -c teamcity --exec /opt/teamcity/TeamCity/bin/teamcity-server.sh start
;;
stop)
start-stop-daemon --stop -c teamcity --exec /opt/teamcity/TeamCity/bin/teamcity-server.sh stop
;;
esac
exit 0
Make sure all the team city files and directory are owned by team city user
cd /opt
chown -R teamcity.teamcity teamcity
Download MySQL JDBC driver from oracle site and copy it to /opt/teamcity/data/.BuildServer/lib/jdbc
Open the Teamcity URL in the browser:
http://teamcity:8111/mnt
Nginx Proxy for Teamcity
apt-get install nginx
Create a file team city under#
cd /etc/nginx/sites-available/
vim teamcity
server {
listen 80;
server_name teamcity;
location / {
proxy_pass http://localhost:8111;
}
}
Check for the syntax
nginx -t -c /etc/nginx/sites-available/default
ln -s /etc/nginx/sites-available/teamcity teamcity
service nginx restart
Now you can access the machine as
http://teamcity/
Monday, April 7, 2014
JIRA upgrade from Ver. 5.2 to 6.2
JIRA upgrade from Ver. 5.2 to 6.2
Steps:
Take jira backup in xml format- Login to JIRA with admin privileges and export the backup
- Copy data folder from JIRA - Attachments /Gravatar/logos
- Copy plugins
- Stop JIRA - /etc/init.d/JIRA stop
- Download the latest jira .bin from Atlassian JIRA download page.
chmod a+x atlassian-jira-X.Y.bin
mkdir -p /opt/atlassian/jira/
- Execute the '.bin' file to start the upgrade wizard.
- choose #2
/opt/atlassian/jira/
Install data directory
/opt/jira6/
- Create mysql database:
mysql> CREATE DATABASE jiradb6 CHARACTER SET utf8 COLLATE utf8_bin;
mysql> GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER,INDEX on jiradb6.* TO 'jirauser'@'localhost' IDENTIFIED BY 'jira_secure_passwd';Query OK, 0 rows affected (0.05 sec)
mysql> flush privileges;
- Download mysql-connector from oracle website and copy it to the JIRA/lib directory.
scp mysql-connector-java-5.1.30-bin.jar /opt/atlassian/jira/lib/
- During the https://
- Copy the attachments,gravatar & logos from old installation to the new. i.e #scp -r attachments/ /opt/jira6/data/
- Make sure all the permission give to jira user and jira group if you are installing on the same machine then the new user will be jira1 instead of jira
Check the logs. ie. tail -f /opt/atlassian/jira/logs/catalina.2014-04-01.log
Saturday, March 15, 2014
Systems
Load - 1
Uptime
10:24 up 6 days, 14:52, 4 users, load averages: 1.74 2.07 2.09
1-5-15 minute load average
System load: avg no. of processes in a runnable or uninterruptible state.
Runnable: Waiting for CPU
Uninterruptible: waiting for I/O
1 CPU with 1 Load means : full utilization/ full load
1 CPU with load 2 : Twice the load that system can handle
Check what kind of load system is under:
CPU
RAM
I/O
Network
As system that is out of memory can be due to I/O load because the system starts swapping and start using the swap space
Top
Helpful in identifying what resource you are running out of system resources, once zeroed down to that then you can try to find out which what process are consuming those resources.
top - 13:35:06 up 227 days, 19:01, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 124 total, 1 running, 123 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 8167620k total, 5987132k used, 2180488k free, 187984k buffers
Swap: 498684k total, 8k used, 498676k free, 5428964k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24332 1956 1036 S 0 0.0 0:08.08 init
2 root 20 0 0 0 0 S 0 0.0 0:00.42 kthreadd
3 root 20 0 0 0 0 S 0 0.0 16:48.59 ksoftirqd/0
6 root RT 0 0 0 0 S 0 0.0 0:33.68 migration/0
7 root RT 0 0 0 0 S 0 0.0 0:47.78 watchdog/0
PID: Process ID- unique number assigned to every process on a system
top -b -n 1 | tee output
Uptime
10:24 up 6 days, 14:52, 4 users, load averages: 1.74 2.07 2.09
1-5-15 minute load average
System load: avg no. of processes in a runnable or uninterruptible state.
Runnable: Waiting for CPU
Uninterruptible: waiting for I/O
1 CPU with 1 Load means : full utilization/ full load
1 CPU with load 2 : Twice the load that system can handle
Check what kind of load system is under:
CPU
RAM
I/O
Network
As system that is out of memory can be due to I/O load because the system starts swapping and start using the swap space
Top
Helpful in identifying what resource you are running out of system resources, once zeroed down to that then you can try to find out which what process are consuming those resources.
top - 13:35:06 up 227 days, 19:01, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 124 total, 1 running, 123 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 8167620k total, 5987132k used, 2180488k free, 187984k buffers
Swap: 498684k total, 8k used, 498676k free, 5428964k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24332 1956 1036 S 0 0.0 0:08.08 init
2 root 20 0 0 0 0 S 0 0.0 0:00.42 kthreadd
3 root 20 0 0 0 0 S 0 0.0 16:48.59 ksoftirqd/0
6 root RT 0 0 0 0 S 0 0.0 0:33.68 migration/0
7 root RT 0 0 0 0 S 0 0.0 0:47.78 watchdog/0
PID: Process ID- unique number assigned to every process on a system
top -b -n 1 | tee output
wa: I/O wait
This number represents the percentage of CPU time that is spent waiting for I/O. It is a particularly valuable metric when you are tracking down the cause of a sluggish system, because if this value is low, you can pretty safely rule out disk or network I/O as the cause
id: CPU idle time
This is one of the metrics that you want to be high. It represents the percentage of CPU time that is spent idle. If you have a sluggish system but this number is high, you know the cause isn’t high CPU load.
st: steal time
If you are running virtual machines, this metric will tell you the percentage of CPU time that was stolen from you for other tasks.
dig
for i in `whois mydomain.com | grep '^Name Server' | awk '{print $NF}'`; do dig @$i www.mydomain; done
Monday, March 10, 2014
Cassandra
* Structured data
* Fast write
* Distributed - Can run of more than 2 nodes
* Column oriented database not like mysql(row oriented database)
* Good for very high volume of data
DynamoDB(amazon was) and HBase are also column base data store.
- Consistency
- Availability
- Partition Tolerance
Install on ubuntu 12.04
http://www.datastax.com/download
Download and untar.
* Fast write
* Distributed - Can run of more than 2 nodes
* Column oriented database not like mysql(row oriented database)
* Good for very high volume of data
DynamoDB(amazon was) and HBase are also column base data store.
- Consistency
- Availability
- Partition Tolerance
Install on ubuntu 12.04
http://www.datastax.com/download
Download and untar.
Data Collection @Heka Way
Tool for high performance data gathering, analysis, monitoring, and reporting.
Heka’s main component is hekad, a lightweight daemon program that can run on nearly any host machine which does the following: Gathers data through reading and parsing log files, monitoring server health, and/or accepting client network connections using any of a wide variety of protocols (syslog, statsd, http, heka, etc.).
Heka is written in Go, Pretty fast.
Inspired by log stash
apps/logs/sytems ==> Heka==> ES/Logfile
Input: Read in
Decoder: Decode info into a message instance
Filters: Parse, process,
Output: send out data, write out to logs, forward to heka.
Plugin: Go or Lua
Checking the logs by tail -f /var/log/* is very time consuming task specially when you have to troubleshoot a tons of logs. Better make a graph from that data and do analysis on top of that.
Heka is one of the latest tool that can help in logs collection and analysis. But you need some other tool as well to get some meaningful data. Heka alone is not enough.It is just a data collection tool.
You can use: Elastic Search, Kibana, Heka to build a complete logs analysis tool.
Install Heka on:
OS: Ubuntu 12.04
Site: https://github.com/mozilla-services/heka/releases
Install the compatible binary:
root@vmhost18:~# wget -c https://github.com/mozilla-services/heka/releases/download/v0.5.0/heka_0.5.0_amd64.deb
root@vmhost18:~# dpkg -i heka_0.5.0_amd64.deb
Create a hekad.toml configuration file in /etc/
root@vmhost18:~# vim /etc/hekad.toml
[LogfileInput]
logfile = "/var/log/auth.log"
decoder = "syslog_decoder"
[syslog_decoder]
type = "PayloadRegexDecoder"
match_regex = '^(?P\w+\s+\d+ \d+:\d+:\d+) (?P\S+) (?P\w+)\[?(?P\d+)?\]?:'
timestamp_layout= 'Jan _2 15:04:05'
[syslog_decoder.message_fields]
Type = "SyslogLog"
Host = "%Host%"
Program = "%Program%"
PID = "%PID%"
[LogOutput]
message_matcher = "TRUE"
[ElasticSearchOutput]
message_matcher = "Type == 'SyslogLog'"
Now point the hekad to the configuration file.
root@vmhost18:~# hekad -config=/etc/hekad.toml | more
2014/03/10 21:05:57 Loading: [LogfileInput]
2014/03/10 21:05:57 Loading: [syslog_decoder]
2014/03/10 21:05:57 Loading: [LogOutput]
2014/03/10 21:05:57 Loading: [ElasticSearchOutput]
2014/03/10 21:05:57 Loading: [ProtobufDecoder]
2014/03/10 21:05:57 Starting hekad...
2014/03/10 21:05:57 Output started: LogOutput
2014/03/10 21:05:57 Output started: ElasticSearchOutput
2014/03/10 21:05:57 MessageRouter started.
2014/03/10 21:05:57 Input started: LogfileInput
2014/03/10 21:05:57 Input 'LogfileInput': Line matches, continuing from byte pos: 95266
Now download and Install elasticserarch
http://www.elasticsearch.org/download/
For ubuntu 12.04 download the .deb and install the same way as we did with Heka.
root@vmhost18:~# wget -c https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.0.1.deb
You need to install java runtime first.
root@tc:~# apt-get install java7-runtime-headless
Reading package lists... Done Building dependency tree Reading state information... Done Note, selecting 'openjdk-7-jre-headless' instead of 'java7-runtime-headless'
root@vmhost18:~# dpkg -i elasticsearch-1.0.1.deb
Selecting previously unselected package elasticsearch. (Reading database ... 70512 files and directories currently installed.) Unpacking elasticsearch (from elasticsearch-1.0.1.deb) ... Setting up elasticsearch (1.0.1) ... Adding system user
elasticsearch' (UID 110) ... Adding new userelasticsearch' (UID 110) with groupelasticsearch' ... Not creating home directory/usr/share/elasticsearch'.NOT starting elasticsearch by default on bootup, please execute
sudo update-rc.d elasticsearch defaults 95 10
In order to start elasticsearch, execute
sudo /etc/init.d/elasticsearch start
Processing triggers for ureadahead ...
root@vmhost18:~# /etc/init.d/elasticsearch start
* Starting Elasticsearch Server
Now install Kibana as well:
http://www.elasticsearch.org/overview/kibana/installation/
root@vmhost18:~# sudo apt-get install nginx
After this operation, 2,350 kB of additional disk space will be used. Do you want to continue [Y/n]?
root@vmhost18:~# sudo service nginx start
Starting nginx: nginx.
root@vmhost18:~# wget -c https://download.elasticsearch.org/kibana/kibana/kibana-3.0.0milestone5.tar.gz
$ tar xvzf kibana-3.0.0milestone5.tar.gz
$root@vmhost18:~# sudo mv kibana-3.0.0milestone5 /usr/share/nginx/www/kibana
http://vmost18/
You can:
Use the multiple output plug-ins of Heka to write the files out to disk for longer retention (text compresses really nicely, and takes up a lot less space than the Elasticsearch data). Split the components up, and build clusters for each piece: an Elasticsearch cluster, a RabbitMQ cluster, an rsyslog host for long file retention, a Heka cluster — with nodes doing different types of message processing;
Other popular Open source routing systems: - Graylog2 (Supports only read/write from a single index), but other release will be supporting multiple index - LogStash
Both of these have builtin elastic search implementations.
Logstash and elastic search are disk and memory intensive as all other java applications are. You don't want to go past 32 GB of RAM dedicated to ElasticSearch and reserve atleast 8 GB to the OS for file-system caching.
Start with 3 servers in your ElasticSearch cluster. This gives you the flexibility to shutdown a server and maintain full use of your cluster.
/etc/security/limits.conf'
# Ensure ElasticSearch can open files and lock memory!
elasticsearch soft nofile 65536
elasticsearch hard nofile 65536
elasticsearch - memlock unlimited
You should also configure ElasticSearch's minimum and maximum pool of memory be set to the same value. This takes care of all the memory allocation at startup, so you don't have threads waiting to get more memory from the kernel
Wednesday, January 15, 2014
ngrep & tcpdump
ngrep -q -d eth0 -W byline host my domain.com and port 80
tcpdump -s 1111 port 80 -w capture_file
tcpdump -nnvvS and src 10.5.2.3 and dst port 3389
# Traffic originating from Mars or Pluto that isn't to the SSH port
tcpdump -vv src mars and not dst port 22
Monitor network traffic / Find the rouge IP address machine
tcpdump -l -n arp | egrep 'arp who-has' | head -100 | awk '{ print $NF }' |sort | uniq -c | sort -n
tcpdump -s 1111 port 80 -w capture_file
tcpdump -nnvvS and src 10.5.2.3 and dst port 3389
# Traffic originating from Mars or Pluto that isn't to the SSH port
tcpdump -vv src mars and not dst port 22
Monitor network traffic / Find the rouge IP address machine
tcpdump -l -n arp | egrep 'arp who-has' | head -100 | awk '{ print $NF }' |sort | uniq -c | sort -n
Friday, January 10, 2014
Vagrant + Puppet + RVM + serverspec
http://serverspec.org/
http://rvm.io/
http://docs.puppetlabs.com/learning/
http://mouapp.com/
What we want to achieve:
Install hypervisor for ubuntu-12.04
Install vagrant
Install virtual box
Create a directory on the system for this project, say KVM
mkdir kvm
Create a Gemfile
vim Gemfile
source 'https://rubygems.org'
gem 'colorize'
gem 'facter', "1.6.5"
gem 'puppet', "2.7.20"
gem 'serverspec'
gem 'puppet-lint'
gem 'fpm'
Create a Rakefile
vim Rakefile
require 'rake'
require 'rspec/core/rake_task'
RSpec::Core::RakeTask.new(:spec) do |t|
t.pattern = 'spec/*/*_spec.rb'
end
Create/initialize a vagrant file : vagrant init
config.vm.box = "precise64"
config.vm.box_url = "http://files.vagrantup.com/precise64.box"
config.vm.network :private_network, ip: "192.168.33.10"
config.vm.provision :shell, inline: "apt-get update -y"
config.vm.provision :puppet do |puppet|
puppet.module_path = "modules"
puppet.manifests_path = "manifests"
puppet.manifest_file = "site.pp"
end
Make two directories as
manifests/site.pp
modules/kvm/manifests/init.pp
Mainfests is plays the role of "what to be done" and Modules plays the role of "how to be done"
Vim init.pp
class l3-kvm {
package {
"kvm-ipxe":
ensure => present;
"python-vm-builder":
ensure => present;
"ubuntu-virt-server":
ensure => present;
}
}
====
vim site.pp
### Global variables ###
#backup settings
File { backup => local }
# Default path
Exec { path => [ "/usr/local/sbin/", "/bin/", "/sbin/" , "/usr/bin/", "/usr/sbin/" ] }
# Centralized backup filebucket
filebucket { local: path => "/var/lib/puppet/clientbucket" }
node /precise64/ {
include kvm
}
rake -T
(in /Users/n/work/techops/kvm)
rake spec # Run RSpec code examples
==
-->
http://rvm.io/
http://docs.puppetlabs.com/learning/
http://mouapp.com/
What we want to achieve:
Install hypervisor for ubuntu-12.04
Install vagrant
Install virtual box
Create a directory on the system for this project, say KVM
mkdir kvm
Create a Gemfile
vim Gemfile
source 'https://rubygems.org'
gem 'colorize'
gem 'facter', "1.6.5"
gem 'puppet', "2.7.20"
gem 'serverspec'
gem 'puppet-lint'
gem 'fpm'
Create a Rakefile
vim Rakefile
require 'rake'
require 'rspec/core/rake_task'
RSpec::Core::RakeTask.new(:spec) do |t|
t.pattern = 'spec/*/*_spec.rb'
end
Create/initialize a vagrant file : vagrant init
config.vm.box = "precise64"
config.vm.box_url = "http://files.vagrantup.com/precise64.box"
config.vm.network :private_network, ip: "192.168.33.10"
config.vm.provision :shell, inline: "apt-get update -y"
config.vm.provision :puppet do |puppet|
puppet.module_path = "modules"
puppet.manifests_path = "manifests"
puppet.manifest_file = "site.pp"
end
Make two directories as
manifests/site.pp
modules/kvm/manifests/init.pp
Mainfests is plays the role of "what to be done" and Modules plays the role of "how to be done"
Vim init.pp
class l3-kvm {
package {
"kvm-ipxe":
ensure => present;
"python-vm-builder":
ensure => present;
"ubuntu-virt-server":
ensure => present;
}
}
====
vim site.pp
### Global variables ###
#backup settings
File { backup => local }
# Default path
Exec { path => [ "/usr/local/sbin/", "/bin/", "/sbin/" , "/usr/bin/", "/usr/sbin/" ] }
# Centralized backup filebucket
filebucket { local: path => "/var/lib/puppet/clientbucket" }
node /precise64/ {
include kvm
}
rake -T
(in /Users/n/work/techops/kvm)
rake spec # Run RSpec code examples
==
user [kvm] $ ls -la
total 80
drwxr-xr-x 18 user staff 612 Jan 10 21:10 .
drwxr-xr-x 55 user staff 1870 Jan 10 15:47 ..
drwxr-xr-x 3 user staff 102 Jan 10 16:10 .bundle
-rw-r--r-- 1 user staff 151 Jan 10 15:59 .gemrc
drwxr-xr-x 13 user staff 442 Jan 10 17:15 .git
-rw-r--r-- 1 user staff 59 Jan 10 16:00 .gitignore
-rw-r--r-- 1 user staff 30 Jan 10 16:00 .rspec
-rw-r--r-- 1 user staff 7 Jan 10 16:00 .ruby-gemset
-rw-r--r-- 1 user staff 16 Jan 10 16:00 .ruby-version
drwxr-xr-x 3 user staff 102 Jan 10 15:40 .vagrant
-rw-r--r-- 1 user staff 136 Jan 10 15:49 Gemfile
-rw-r--r-- 1 user staff 1213 Jan 10 16:10 Gemfile.lock
-rw-r--r--@ 1 user staff 353 Jan 10 17:12 README.md
-rw-r--r-- 1 user staff 124 Jan 10 16:17 Rakefile
-rw-r--r-- 1 user staff 3413 Jan 10 17:06 Vagrantfile
drwxr-xr-x 3 user staff 102 Jan 10 16:58 manifests
drwxr-xr-x 3 user staff 102 Jan 10 16:57 modules
drwxr-xr-x 4 user staff 136 Jan 10 16:17 spec
total 80
drwxr-xr-x 18 user staff 612 Jan 10 21:10 .
drwxr-xr-x 55 user staff 1870 Jan 10 15:47 ..
drwxr-xr-x 3 user staff 102 Jan 10 16:10 .bundle
-rw-r--r-- 1 user staff 151 Jan 10 15:59 .gemrc
drwxr-xr-x 13 user staff 442 Jan 10 17:15 .git
-rw-r--r-- 1 user staff 59 Jan 10 16:00 .gitignore
-rw-r--r-- 1 user staff 30 Jan 10 16:00 .rspec
-rw-r--r-- 1 user staff 7 Jan 10 16:00 .ruby-gemset
-rw-r--r-- 1 user staff 16 Jan 10 16:00 .ruby-version
drwxr-xr-x 3 user staff 102 Jan 10 15:40 .vagrant
-rw-r--r-- 1 user staff 136 Jan 10 15:49 Gemfile
-rw-r--r-- 1 user staff 1213 Jan 10 16:10 Gemfile.lock
-rw-r--r--@ 1 user staff 353 Jan 10 17:12 README.md
-rw-r--r-- 1 user staff 124 Jan 10 16:17 Rakefile
-rw-r--r-- 1 user staff 3413 Jan 10 17:06 Vagrantfile
drwxr-xr-x 3 user staff 102 Jan 10 16:58 manifests
drwxr-xr-x 3 user staff 102 Jan 10 16:57 modules
drwxr-xr-x 4 user staff 136 Jan 10 16:17 spec
====
more .gemrc
:backtrace: false
:benchmark: false
:bulk_threshold: 1000
:sources:
- http://rubygems.org/
:update_sources: true
:verbose: true
gem: --no-ri --no-rdoc
==
more .gitignore
.vagrant
.DS_Store
scripts/build
*.box
.bundle
*.swp
*.swo
====
more .rspec
--colour
-f
progress
-f
doc
==
more .ruby-gemset
puppet
==
more .ruby-version
ruby-1.9.2-p290
==
vim kvm/spec/default
require 'spec_helper'
describe package('ubuntu-virt-server') do
it { should be_installed }
end
describe package('python-vm-builder') do
it { should be_installed }
end
describe package('kvm-ipxe') do
it { should be_installed }
end
#describe file('/etc/httpd/conf/httpd.conf') do
# it { should be_file }
# it { should contain "ServerName default" }
#end
==
puppet apply --verbose --debug --modulepath modules manifests/site.ppFriday, January 3, 2014
Empty /tmp directory in linux
11 10 * * * /usr/bin/find /tmp/ -maxdepth 2 -name "*" -not -name tmp -exec rm -rf {} \; > /dev/null 2>&1
Monday, December 2, 2013
Saturday, October 26, 2013
Customized zabbix monitoring
# Customized disk i/o monitoring
UserParameter=custom.vfs.dev.read.ops[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$4}'
UserParameter=custom.vfs.dev.read.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$7}'
UserParameter=custom.vfs.dev.write.ops[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$8}'
UserParameter=custom.vfs.dev.write.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$11}'
UserParameter=custom.vfs.dev.io.active[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$12}'
UserParameter=custom.vfs.dev.io.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$13}'
UserParameter=custom.vfs.dev.read.sectors[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$6}'
UserParameter=custom.vfs.dev.write.sectors[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$10}'
# Customized MySQL monitoring
UserParameter=mysql.daily,php /etc/zabbix/scripts/mysql.php live zabbix xxxxxxxxx
UserParameter=mysql.live,php /etc/zabbix/scripts/mysql.php live zabbix xxxxxxxx
# Pacemaker monitoring
UserParameter=pacemaker.status, sudo /usr/sbin/crm_mon -s |cut -f2 -d:
UserParameter=pacemaker-ipresource.status, sudo /usr/sbin/crm_mon -1 |grep "heartbeat:IPaddr2" |awk '{print $3}'
UserParameter=pacemaker-iparpresource.status, sudo /usr/sbin/crm_mon -1 |grep "heartbeat:SendArp" |awk '{print $3}'
UserParameter=pacemaker-vip.master, sudo /usr/sbin/crm_mon -1 |grep "heartbeat:IPaddr2" |awk '{print $4}'
UserParameter=pacemaker-arp.master, sudo /usr/sbin/crm_mon -1 |grep "heartbeat:SendArp" |awk '{print $4}'
UserParameter=pacemaker.ha.failchk, /usr/bin/sudo /usr/sbin/crm_mon -1| /bin/egrep -i 'Failed actions'
UserParameter=pacemaker.ha.onlinechk, /usr/bin/sudo /usr/sbin/crm_mon -1| /bin/egrep -i 'offline'
UserParameter=pacemaker.ha.cleanchk, /usr/bin/sudo /usr/sbin/crm_mon -1| /bin/egrep -i 'UNCLEAN'
UserParameter=redis_stats[*],/etc/zabbix/scripts/redis.pl $1 $2 $3
Website monitoring
# mysite monitoring
UserParameter=mysite.check,wget --no-check-certificate -O- https://mysite.com/login
Local health check
# monitoring
UserParameter=app.myadmin.health, /usr/bin/w3m -dump -no-cookie http://localhost:8080/health | sed 's///g' | grep -wc 'appStatus=\"1\"'
Mongo Monitoring
UserParameter=mongo.uptime, /etc/zabbix/scripts/mongo_plugin.py serverStatus uptime
UserParameter=mongo.current.connections, /etc/zabbix/scripts/mongo_plugin.py serverStatus connections current
UserParameter=mongo.available.connections, /etc/zabbix/scripts/mongo_plugin.py serverStatus connections available
# Custom LDAP monitoring
UserParameter=ldap.search.status, /usr/bin/ldapsearch -x -b '' -s base '(objectclass=*)' namingContexts | grep -wc "Success"
Mysql-Slave monitoring
# MySQL Slave Process monitoring
# MySQL Slave Process monitoring
UserParameter=mysql.ha.Slave_IO_Running, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Slave_IO_Running | awk '{print $2}'
UserParameter=mysql.ha.Last_SQL_Errno, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Last_SQL_Errno | awk '{print $2}'
UserParameter=mysql.ha.Seconds_Behind_Master, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Seconds_Behind_Master | awk '{print $2}'
UserParameter=mysql.ha.Slave_SQL_Running, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Slave_SQL_Running | awk '{print $2}'
UserParameter=mysql.ha.Last_Errno, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Last_Errno | awk '{print $2}'
UserParameter=mysql.ha.Last_IO_Errno, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxx" "mysql" -se "show slave status\G" | grep Last_IO_Errno | awk '{print $2}'
#monitor SSL cert
UserParameter=cert_check[*],/etc/zabbix/externalscripts/ssl_check.sh $1
(You have to create a template in zabbix based on this )
UserParameter=custom.vfs.dev.read.ops[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$4}'
UserParameter=custom.vfs.dev.read.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$7}'
UserParameter=custom.vfs.dev.write.ops[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$8}'
UserParameter=custom.vfs.dev.write.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$11}'
UserParameter=custom.vfs.dev.io.active[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$12}'
UserParameter=custom.vfs.dev.io.ms[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$13}'
UserParameter=custom.vfs.dev.read.sectors[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$6}'
UserParameter=custom.vfs.dev.write.sectors[*],cat /proc/diskstats | grep $1 | head -1 | awk '{print $$10}'
# Customized MySQL monitoring
UserParameter=mysql.daily,php /etc/zabbix/scripts/mysql.php live zabbix xxxxxxxxx
UserParameter=mysql.live,php /etc/zabbix/scripts/mysql.php live zabbix xxxxxxxx
# Pacemaker monitoring
UserParameter=pacemaker.status, sudo /usr/sbin/crm_mon -s |cut -f2 -d:
UserParameter=pacemaker-ipresource.status, sudo /usr/sbin/crm_mon -1 |grep "heartbeat:IPaddr2" |awk '{print $3}'
UserParameter=pacemaker-iparpresource.status, sudo /usr/sbin/crm_mon -1 |grep "heartbeat:SendArp" |awk '{print $3}'
UserParameter=pacemaker-vip.master, sudo /usr/sbin/crm_mon -1 |grep "heartbeat:IPaddr2" |awk '{print $4}'
UserParameter=pacemaker-arp.master, sudo /usr/sbin/crm_mon -1 |grep "heartbeat:SendArp" |awk '{print $4}'
UserParameter=pacemaker.ha.failchk, /usr/bin/sudo /usr/sbin/crm_mon -1| /bin/egrep -i 'Failed actions'
UserParameter=pacemaker.ha.onlinechk, /usr/bin/sudo /usr/sbin/crm_mon -1| /bin/egrep -i 'offline'
UserParameter=pacemaker.ha.cleanchk, /usr/bin/sudo /usr/sbin/crm_mon -1| /bin/egrep -i 'UNCLEAN'
UserParameter=redis_stats[*],/etc/zabbix/scripts/redis.pl $1 $2 $3
Website monitoring
# mysite monitoring
UserParameter=mysite.check,wget --no-check-certificate -O- https://mysite.com/login
Local health check
# monitoring
UserParameter=app.myadmin.health, /usr/bin/w3m -dump -no-cookie http://localhost:8080/health | sed 's///g' | grep -wc 'appStatus=\"1\"'
Mongo Monitoring
UserParameter=mongo.uptime, /etc/zabbix/scripts/mongo_plugin.py serverStatus uptime
UserParameter=mongo.current.connections, /etc/zabbix/scripts/mongo_plugin.py serverStatus connections current
UserParameter=mongo.available.connections, /etc/zabbix/scripts/mongo_plugin.py serverStatus connections available
# Custom LDAP monitoring
UserParameter=ldap.search.status, /usr/bin/ldapsearch -x -b '' -s base '(objectclass=*)' namingContexts | grep -wc "Success"
Mysql-Slave monitoring
# MySQL Slave Process monitoring
# MySQL Slave Process monitoring
UserParameter=mysql.ha.Slave_IO_Running, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Slave_IO_Running | awk '{print $2}'
UserParameter=mysql.ha.Last_SQL_Errno, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Last_SQL_Errno | awk '{print $2}'
UserParameter=mysql.ha.Seconds_Behind_Master, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Seconds_Behind_Master | awk '{print $2}'
UserParameter=mysql.ha.Slave_SQL_Running, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Slave_SQL_Running | awk '{print $2}'
UserParameter=mysql.ha.Last_Errno, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxxxx" "mysql" -se "show slave status\G" | grep Last_Errno | awk '{print $2}'
UserParameter=mysql.ha.Last_IO_Errno, /usr/bin/mysql -h "localhost" -u "zabbix" -p"xxxxx" "mysql" -se "show slave status\G" | grep Last_IO_Errno | awk '{print $2}'
#monitor SSL cert
UserParameter=cert_check[*],/etc/zabbix/externalscripts/ssl_check.sh $1
(You have to create a template in zabbix based on this )
Thursday, October 17, 2013
cannot find device br0 failed to bring up br0
Make sure you have bridge-utils package installed.
apt-get install bridge-utils
apt-get install bridge-utils
Sunday, October 6, 2013
Import a VM in KVM
Virt-Install
virt-install --name vmhost9-vm01 --ram 8192 --vcpus=4 --disk path=/var/lib/libvirt/images/vmhost9-vm01.img,size=20 -v --accelerate --os-type=linux --keymap=en-us --network=bridge:br0 --importSunday, August 18, 2013
tcpdump for X-Forwarded-For header
How to take tcp dump for a service that is running on port 4002
#tcpdump -vvvs 1024 -l -A -w /tmp/web-1.pcap tcp port 4002
or
Take a dump to some specific network interface on some specific port.
tcpdump -i eth0.12 -s0 -w /tmp/web-1.pcap port 4002
How to read the tcpdump
tcpdump -X -vv -r web-1.pcap
or
use wireshark
Friday, August 16, 2013
Mysql dump and restore it on remote machine
SourceHost
#mysqldump --opt --skip-lock-tables -umyuser -pmy-secret-password teamcity --extended-insert --routines --add-drop-table | mysql -ubackup -pbackup -hremotehost.myodmain.com teamcity
If you want to reset the root password
mysql --defaults-file=/etc/mysql/debian.cnf
update mysql.user set password=PASSWORD('password') where user='root';Wednesday, July 17, 2013
mount
# df
# cat /etc/fstab
# mount -a
# umount -a
sudo fdisk -l
Find the newly added hard disk,
To create the partition on the second Hard drive,
sudo fdisk /dev/sdx
u
n
p
w
Now we need to format our newly created partition using the following command:
sudo mkfs /dev/sdb1 -t ext4
verify
sudo fdisk -l
mount the newly created sdb1 partition into other directory
or
{
cd /mnt/ sudo mkdir 2ndHDD sudo chmod 0777 2ndHDD ls -l
sudo mount /dev/sdb1 /mnt/2ndHDD -t ext4
sudo chmod 0777 2ndHDD
touch /mnt/2ndHDD/test.txt ls /mnt/2ndHDD/*
}
mount -t ext4 -v /dev/sdb1 /opt/repository/myDir
sudo vim /etc/fstab
/dev/sdb1 /opt/repository/myDir ext4 defaults 0 1
sudo mount -a
Thursday, May 30, 2013
Vagrant: * Unknown configuration section 'berkshelf'.
Berkshalf vagrant variant has been renamed by its maintainer at https://github.com/RiotGames/vagrant-berkshelf Users using the old command will face the following error when executing "vagrant up": Vagrant: * Unknown configuration section 'berkshelf'.
Solution:
sudo vagrant plugin install vagrant-berkshelf
vagrant up
Friday, May 10, 2013
File Share using Apache
File Share using Apache
Apache is pretty useful for sharing files on network particularly on LAN. Here is how to map an external folder to an url on your apache server. Lets assume your home directory is ABC and the path of the folder that you want to share is /var/log/weblogs. And you want to access contents of this folder at url /weblogs.
Change directory to /etc/apache2/sites-enabled. And create file named downloads with the following contents.
Alias "/weblogs" "/var/log/weblogs/"
Directory "/var/log/weblogs/"
AllowOverride None
Options Indexes
Order allow,deny
Allow from all
/Directory
Save the file and close it. Now restart the apache by issuing following command.
sudo apache2ctl restart
Now test everything is working as expected by going to following url in your browser.
http://localhost/weblogs
Alias "/weblogs" "/var/log/weblogs/"
Directory "/var/log/weblogs/"
AllowOverride None
Options Indexes
Order allow,deny
Allow from all
/Directory
sudo apache2ctl restart
http://localhost/weblogsWednesday, May 1, 2013
Reset forgotten mysql password
This works for ubuntu/Debain only & not for red hat/Centos
# /etc/init.d/mysql stop
# mysqld_safe --skip-grant-tables &
$ mysql -u root
mysql> use mysql;
mysql> update user set password=PASSWORD("password") where User='root';
mysql> flush privileges;
mysql> quit
# /etc/init.d/mysql stop
# /etc/init.d/mysql start
$ mysql -u root -p Take Full backup of Mysqlmysqldump -u root -ppassword --all-databases > /tmp/all-database.sql Restore DBmysql -u root -ppassword </tmp/all-database.sql
Subscribe to:
Posts (Atom)